Project 03
ADAPT-SQL
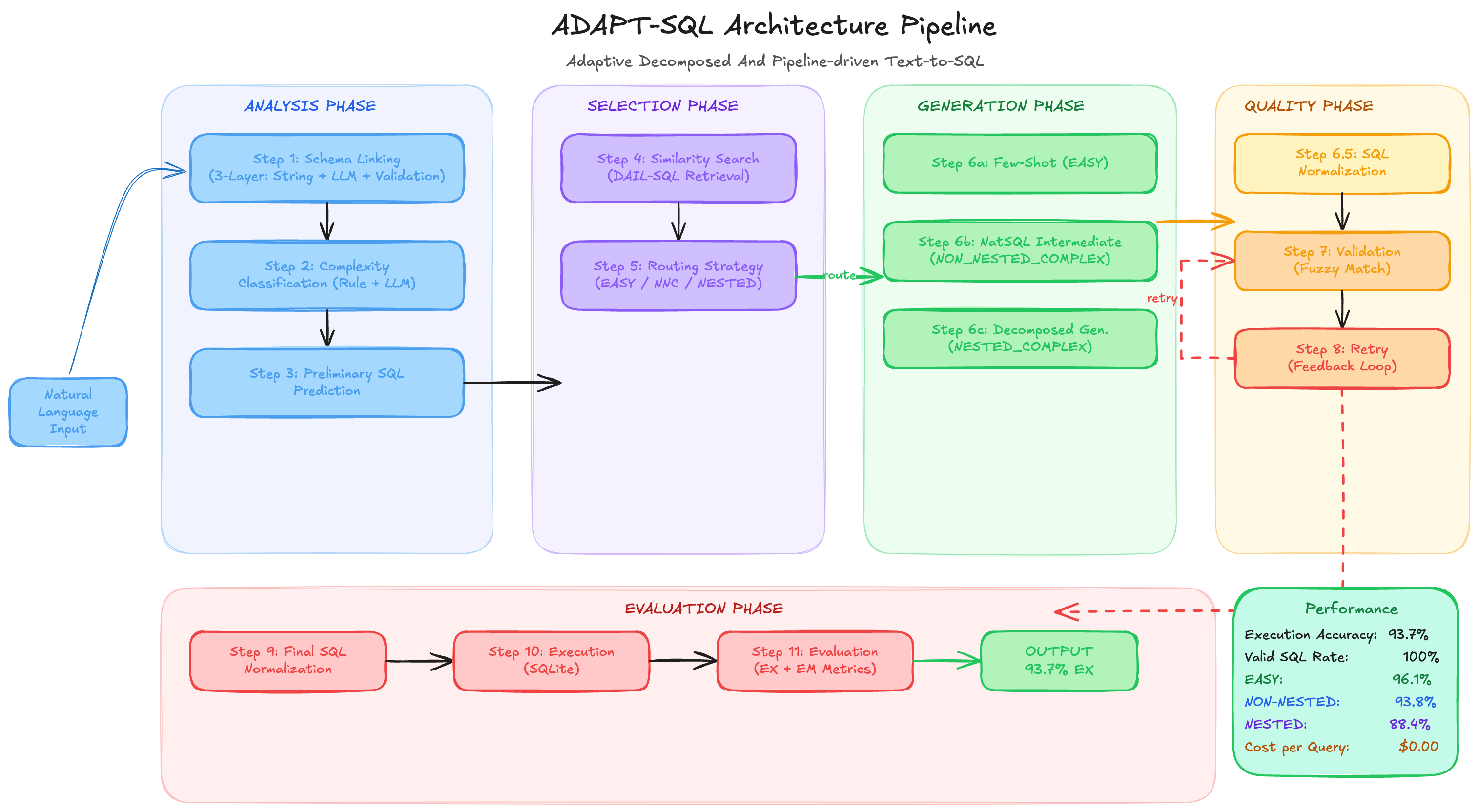
Text-to-SQL is usually framed as a model problem. ADAPT-SQL is an argument that it is mostly a pipeline engineering problem. Holding the pipeline fixed and swapping three architecturally different models (Gemma4-31B dense, Qwen3-Coder-30B MoE at roughly 3B active, Qwen3-235B MoE at roughly 22B active), they score within 0.8 points on 89% of Spider queries. The 93.7% execution accuracy comes from the engineering, not the model.
The pipeline has 11 steps. The highest-impact is three-layer schema linking: lexical string matching, then LLM semantic linking, then FK-graph connectivity inference. The graph traversal finds the join path between tables that are not directly mentioned in the question, where most schema linking systems quietly fail.
Complexity classification routes each query to one of three generation strategies. EASY queries use few-shot prompting (96.1%). NON_NESTED queries use NatSQL IR (93.8%), a grammar constraint that prevents invalid set operations at the generation level. NESTED_COMPLEX queries are decomposed into sub-problems (88.4%).
In-context example selection uses structural reranking over FAISS retrieval: semantic similarity weighted at 0.5, structural similarity at 0.3. Structural similarity (how similar the SQL skeletons are) is the more predictive signal for whether an example will help.
A 6-checker validation chain runs after every generated query. Failures feed the specific error back as a prompt for retry: not a generic re-roll, but the exact constraint violated. This recovers 13-19% of initially failing queries.
Architecture only diverges on nested-complex queries, where MoE routing opens a 4.4-point gap over a dense architecture with more active parameters. On standard queries, active parameter count predicts nothing.
What I Learned
- Ablation is the only way to isolate what actually helpsMost Text-to-SQL systems co-optimize model, prompt, retrieval, and generation simultaneously. Without holding everything fixed and removing one component at a time, you cannot know if a result came from the model or the pipeline. The finding that models score within 0.8pp on 89% of queries only becomes visible through controlled ablation.
- NatSQL as a grammar constraint, not a modelNatSQL is not a different generation strategy. It is a constrained dialect that makes certain syntactic errors structurally impossible. Using it as an intermediate representation means the generation step cannot produce invalid set operations for non-nested queries. Intermediate representations can replace post-hoc validation.
- Structural similarity outweighs semantic similarity for few-shot example selectionSemantic similarity finds questions with similar meaning. Structural similarity finds examples where the SQL skeleton has the same shape: same number of JOINs, same aggregation depth, same set operation type. SQL correctness is structural, so the latter is the more predictive signal. Weighting structural at 0.3 and semantic at 0.5 outperforms semantic-only retrieval by 4.8 points.
- Retry with the error, not a fresh promptRe-generating from scratch on failure rarely works. The model makes the same mistake. Passing the specific validation error back as a prompt, like 'column users.email does not exist in table accounts', gives the model the exact constraint it violated. This precision is why the retry loop recovers 13-19% of failing queries.
Tech Stack
Links